Guide to Structured Web Data Consumption: How to get instant access to news, blogs, and online discussions

Hundreds of entrepreneurs, researchers, and data scientists contact us daily with questions about accessing structured web data. We put together our answers our new guide to Structured Web Data Consumption.

The consumerization of web data
It’s easy to fall into the trap of building a proprietary crawling and data structuring solution tailored to a particular study or application. While this approach does get the job done, it is limited at best and in most cases not feasible. Crawling and structuring open web data at scale is simply not a task one individual can tackle. Fortunately, economies of scale enable anyone with even a modest budget to extract structured datasets. In fact, you can use the very same enterprise class technology trusted by a growing number of industry leaders. Since you pay per use, the solution addresses the needs and budget constraints of any consumer of data – ranging from students to large scale commercial data operations.
The Challenge of Coverage
When it comes to data measurement, the first question is often “How much of the web do you crawl?”. Unfortunately, any figure or percentage estimate would be misleading at best. The web is a constantly evolving and fragmented collection of unstructured data. Extracting that data and then structuring it as a prerequisite for analysis means making intelligent compromises. From a business and technology perspective, the real question is “what is the best possible coverage you can provide given finite resources?” Answering that question is an ongoing technological challenge that is driving phenomenal growth of the emerging Data-as-a-Service solutions category.
Dataset breakdown – extracted, inferred, and enriched fields
Webz.io structures web data into extracted fields, inferred fields, and enriched fields. Every source we crawl is identified as a “post”, an indexed record matching a specific news article, blog post, or online discussion post. We then extract standard fields common to these source types, including URL, title, body text, and associated online discussion posts such as comments.
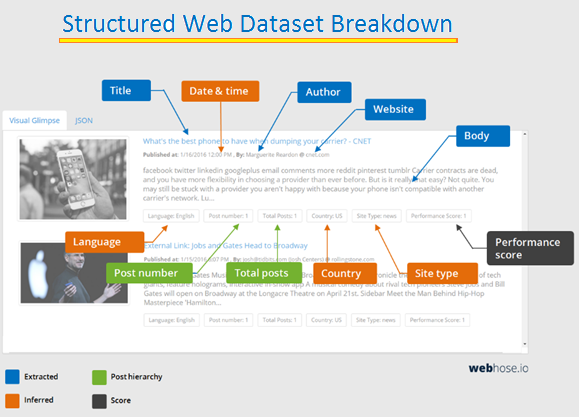
Learn more about post hierarchy, field types, and scores>
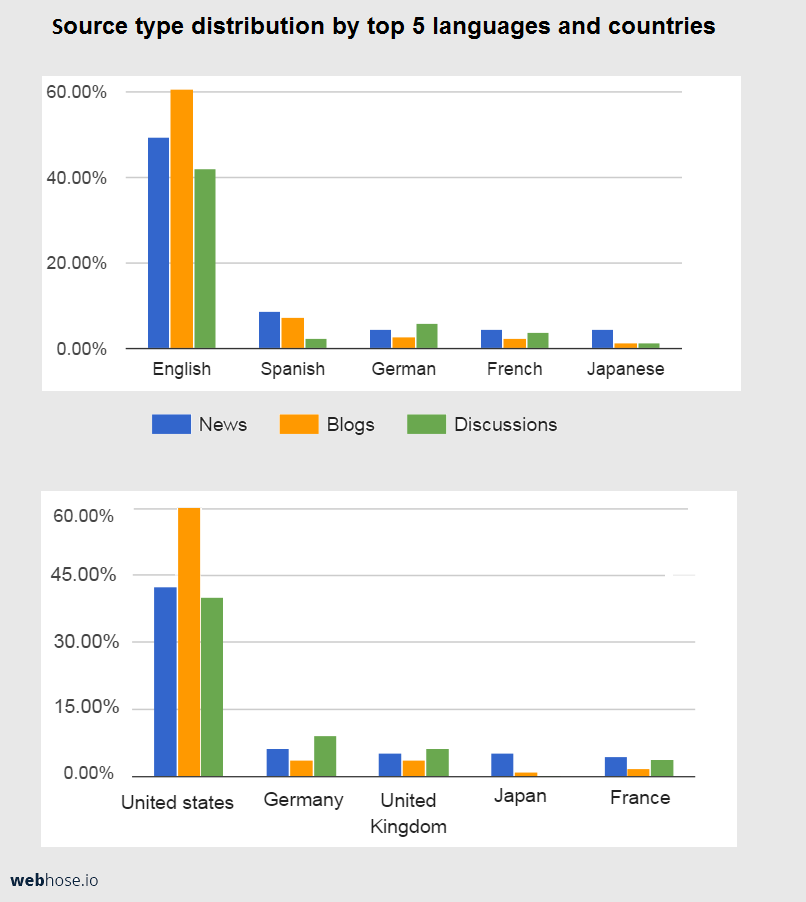
Webz.io focuses on three types of web data sources:
- News media – news agencies, article publications, and magazines
- Blogs – individual bloggers, large blogging services such as blogger, brands
- Online discussions – message boards, commenting widgets, and review sites